
|
Hey, I wrote these slides for a different talk and had to cut them out. But I think they’re ok! # |

|
What the hell are we trying to do in software? Well, if we’re talking about an application on the internet, I can think of two big goals. # |

|
We have to ship a bunch of stuff. It’s our job as engineers to change things. That is the job. # |

|
And, we don’t want to destroy everything of value that we’ve already built when we do that. # |

|
The first thing you might notice about those goals is that the second one isn’t possible. Or at least all industry experience suggests this. No significant web service yet conceived has never been down. S3 was down a while back. It was chaos. We can take this as a fact of life. Production breaks. # |

|
The only thing we can do then, here on Earth, is try to minimize the length of time that production is broken. # |

|
Anytime we deploy code, there’s some chance that it’s going to break something. We’ve got a probability of breakage, given a deploy. # |

|
And that gets multiplied by the number of times we try to deploy code. # |

|
And then the time that production is down over some interval is the average time it takes us to fix it, times the number of times we take it down. # |

|
The key insight of continuous delivery is that these aren’t fixed quantities. In practice each of them actually depends on the values you pick for the others. # |

|
It turns out that if you crank up the number of deploys you do, the probability that any given deploy breaks declines. # |

|
The time to fix a given broken deploy also declines if you crank up the number of deploys. Deploys—the first term—obviously increase. But I have become a believer that cranking it up is a win holistically, and has the practical effect of minimizing the value of this formula. # |

|
One reason this is true is that the longer it’s been since we last deployed, the more likely it is that the next deploy is going to break. # |

|
If you haven’t deployed since last month, the deploy tools themselves are most likely broken. You’ve either broken them directly with untested changes, or you’ve got IP addresses hardcoded in there and your infrastructure has changed, or who knows what. # |

|
Another less-than-intuitive thing we should consider is that if deploys take a long time, this is dangerous. Even if they work reliably, slow deploys are not neutral. # |

|
If the deploy tooling isn’t made fast, there’s probably a faster and more dangerous way to do things and people will do that instead. They’ll replace running docker containers by hand. They’ll hand-edit files on the hosts. So we want to make the “right way” to ship code also the laziest possible way. # |

|
Even if we could avoid shipping quickly most of the time, we’ll occasionally have to push in a big hurry. # |

|
Bad things happen in production, and they have to mitigated quickly. An actively-exploited SQL injection flaw is one example. These things come up in real life. # |

|
And when they do, you don’t want to be trying to use a poorly tested “fast path” in a crisis. That’s making an already bad situation downright dangerous. # |

|
If you deploy infrequently, that also means you wrote the code farther into the past. That’s bad. # |
|
You have great understanding of what code is doing when you’re writing it. Then your comprehension of it gets strictly worse over time. After a week or so you may barely have any idea what it was you were trying to accomplish. This is bad news if you find yourself having to debug a problem with it in production after deploying it. # |

|
And if you’re deploying infrequently, you’re also shipping a lot more code at once. This is a terrible idea. # |
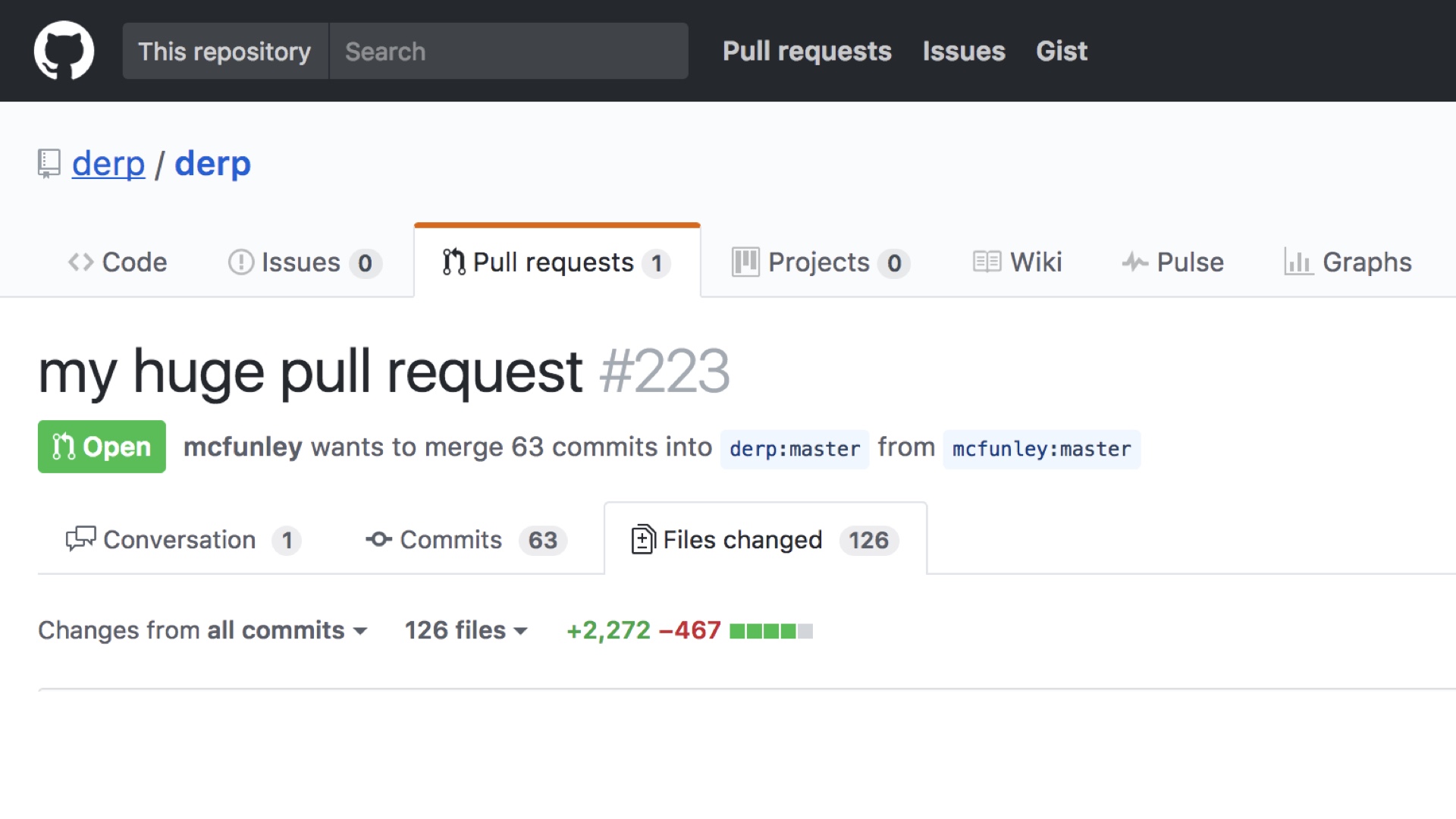
|
Every senior engineer knows to look at this page with a high level of panic. This is a merge that is definitely not going to go well. You can feel it in your bones. # |
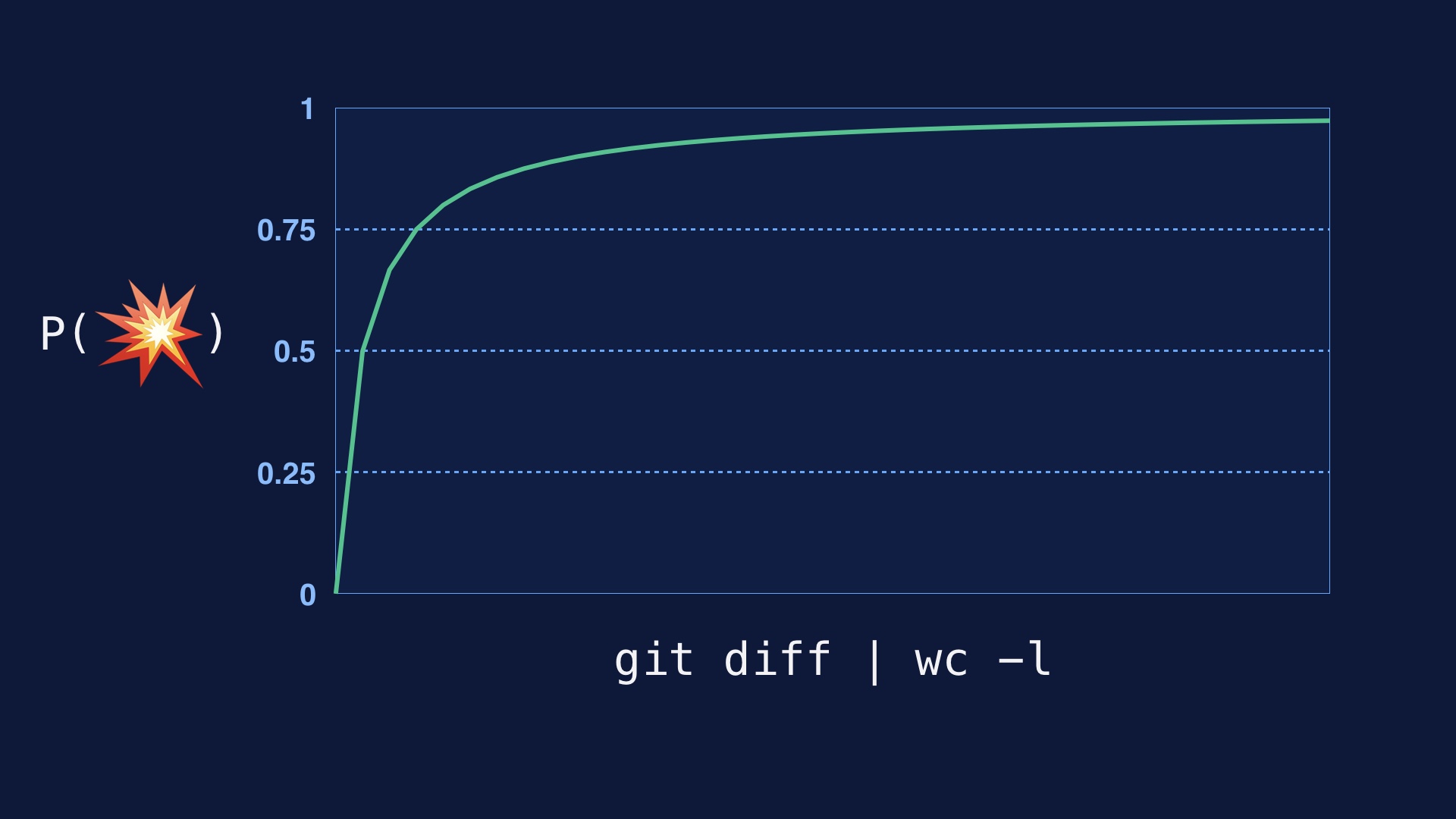
|
Every single line of code you deploy has some probability of breaking the site. So if you deploy a lot of lines of code at once, you’re going break the site. You just will. # |

|
You also stand a better chance of inspecting code for correctness the less of it there is. # |
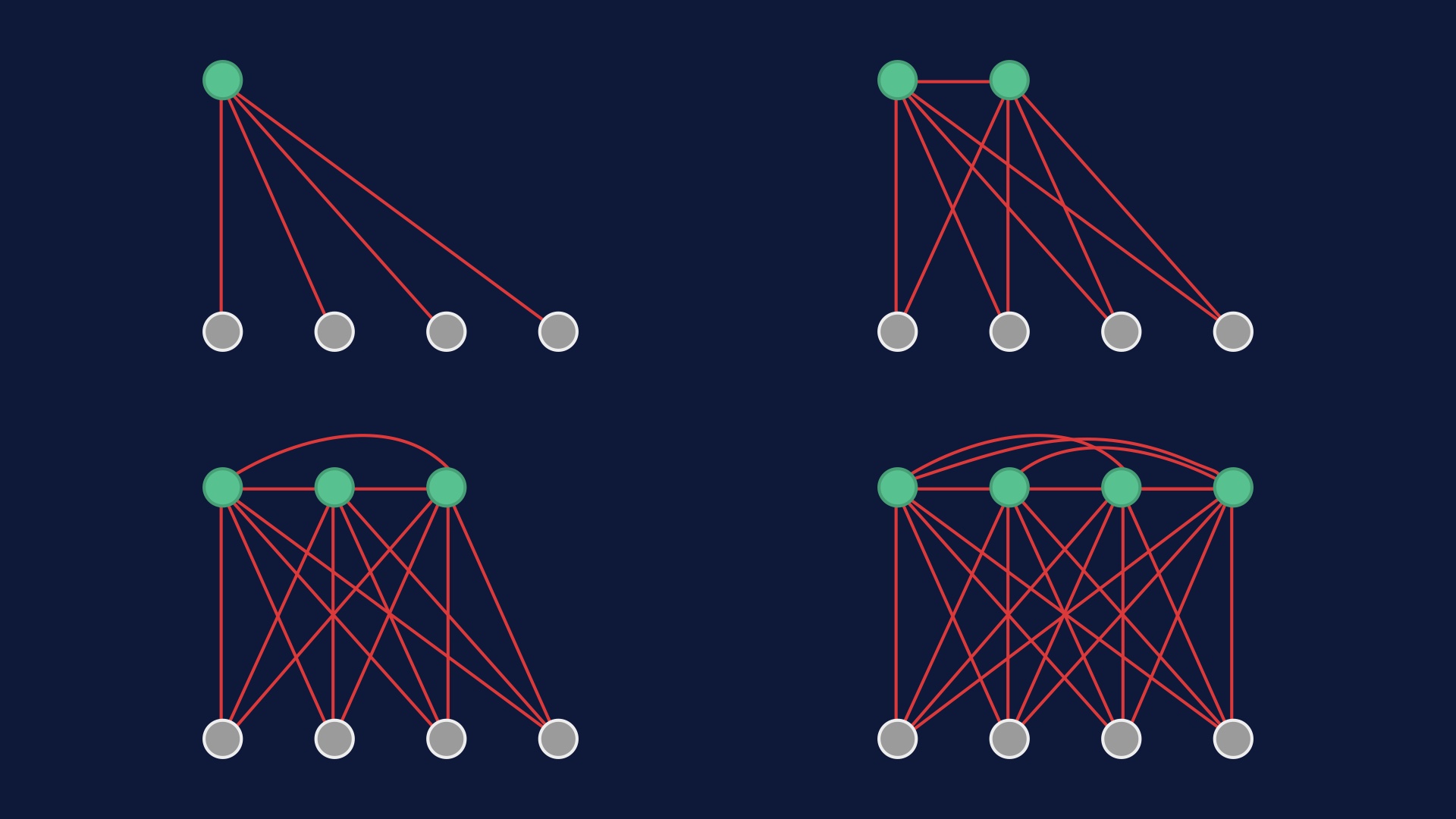
|
When you change a bunch of lines, in theory each of them might interact with every other thing you have. The author of the commit can have a pretty good idea of which potential interactions are important, so coding is generally a tractable activity. It sort of works anyway. But someone tasked with reviewing the code has much less context. # |
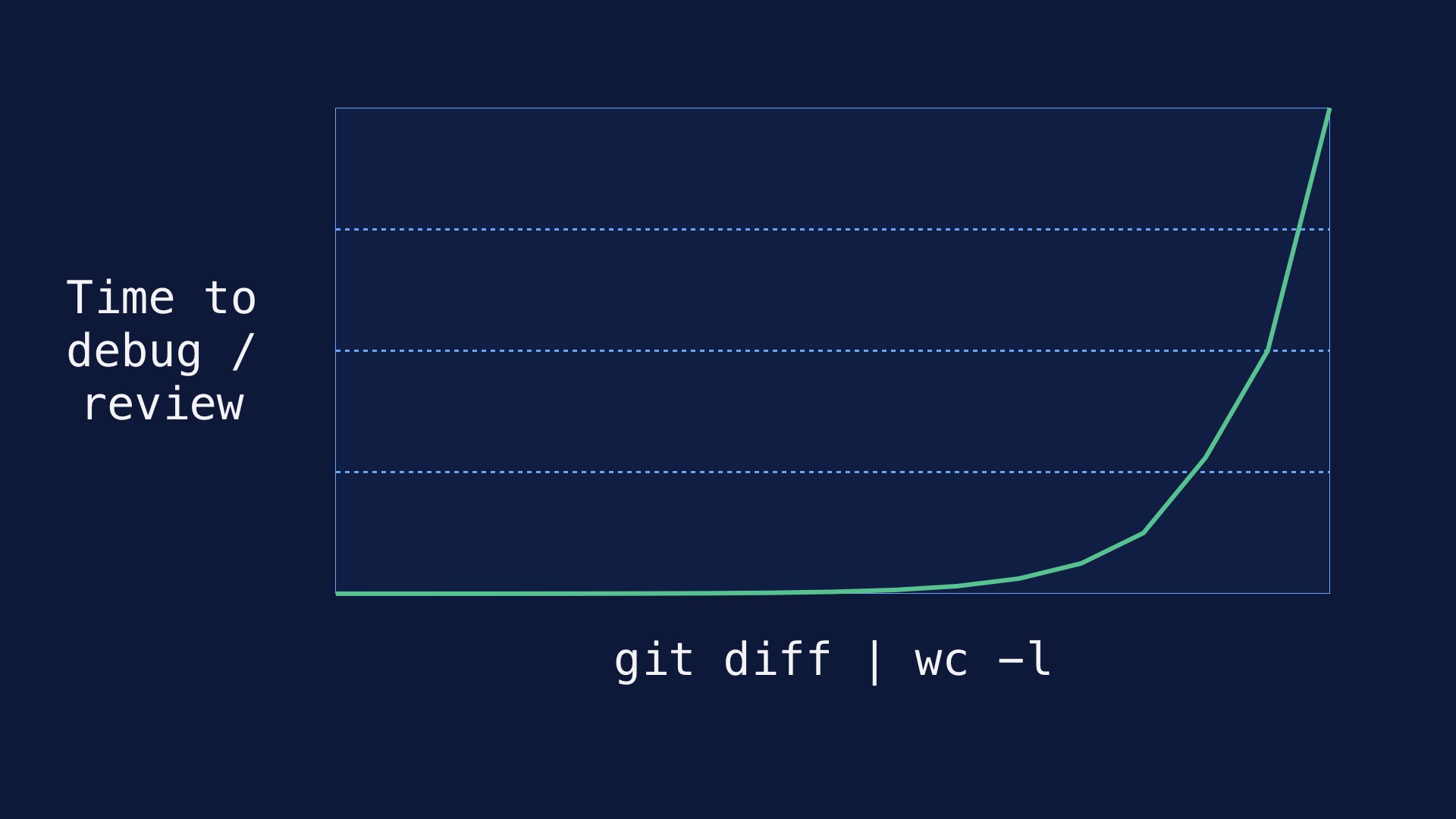
|
So the amount of effort it takes to wrap your head around a changeset scales quadratically with the number of lines in it. Two small diffs tend to be easier to check for correctness than one large one. If you’re trying to look at a diff that was deployed and figure out what went wrong with it, the problem is the same. # |

|
One solution to all of these problems would be to just avoid pushing lines of code. But we’d get fired pretty quickly if we did that. We have to ship a lot of code. # |

|
Deploying often means that we’ve exercised all of our tooling recently, and we can be confident that it works. # |

|
Deploying sufficiently often means the deploy pipeline has to be fast. Which means there’s not a faster hacky way to deploy. Deploying often keeps us on the blessed path. # |

|
That also means that when something breaks, we’ll have a short path to fixing it. # |

|
Deploying often minimizes the chances that any given deploy is broken. We’ll get a lot of little deploys through with no problems. If we deploy in huge chunks, we’ll definitely have problems with them in production. # |

|
And when we encounter faults, we’ll more clearly understand what we were trying to accomplish. # |

|
And we’ll have an easier time figuring out what’s broken if we just pushed a few dozen lines. The broken thing is something in that dozen lines. Not, as in other cases, some small thing in an epic pile of thousands of lines of code. # |

|
# |